分词
分词是 LLMs 中的一个基础步骤。它是将文本分解为更小的子词单元(称为 token)的过程。我们最近在 Mistral AI 开源了我们的分词器。本指南将带你了解分词的基础知识、我们开源的分词器的详细信息以及如何在 Python 中使用我们的分词器。
什么是分词?
分词是文本处理和建模的第一步也是最后一步。文本需要在我们的模型中表示为数字,以便模型能够理解。分词将文本分解为 token,每个 token 被分配一个数字表示或索引,这些可以用于输入到模型中。在典型的 LLM 工作流程中:
- 我们首先使用分词器将输入文本编码成 token。在分词器的词汇表中,每个唯一的 token 都被分配一个特定的索引号。
- 文本被分词后,这些 token 会通过模型,模型通常包含一个嵌入层和 Transformer 块。嵌入层将 token 转换为捕获语义的密集向量。请查看我们的嵌入指南了解详情。然后 Transformer 块处理这些嵌入向量以理解上下文并生成结果。
- 最后一步是解码,它将输出 token 还原回人类可读的文本。这通过将 token 映射回它们在分词器词汇表中对应的词来完成。
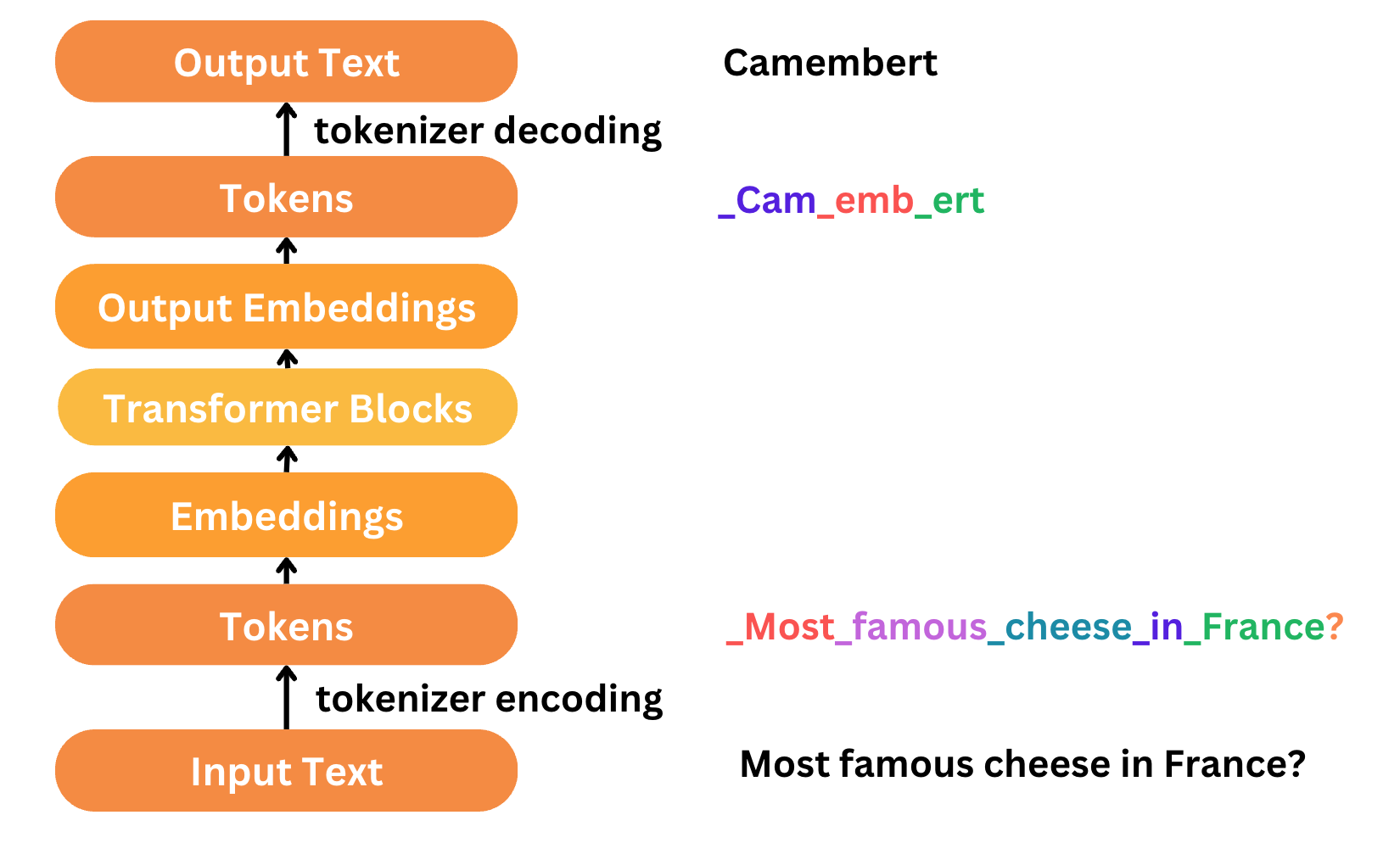
大多数人只对文本进行分词。我们的第一个版本包含分词功能。我们的分词器超越了通常的文本 <-> token 转换,还添加了工具和结构化对话的解析。我们还发布了用于我们 API 的验证和规范化代码。具体来说,我们使用了控制 token,它们是特殊 token,用于指示不同类型的元素。这些 token 不被视为字符串,而是直接添加到代码中。请注意,我们仍在迭代改进分词器。情况可能会发生变化,这是当前的状况。
我们发布了三个版本的分词器,为不同的模型集提供支持。
- v1:
mistral-embed、open-mixtral-8x7b - v2:
mistral-small-2402(已弃用)、mistral-large-2402 - v3:
open-mixtral-8x22b、mistral-large-latest、mistral-small-latest、open-mistral-7b - v3 (tekken):
open-mistral-nemo、ministral-8b-latest
本指南将重点介绍我们最新的 v3 (tekken) 分词器和 v3 分词器。
v3 (tekken) 分词器
自然语言处理 (NLP) 中有几种分词方法,用于将原始文本转换为 token,例如词级分词、字符级分词和子词级分词(包括字节对编码 (BPE))。我们最新的分词器 tekken 使用带有 Tiktoken 的字节对编码 (BPE)。
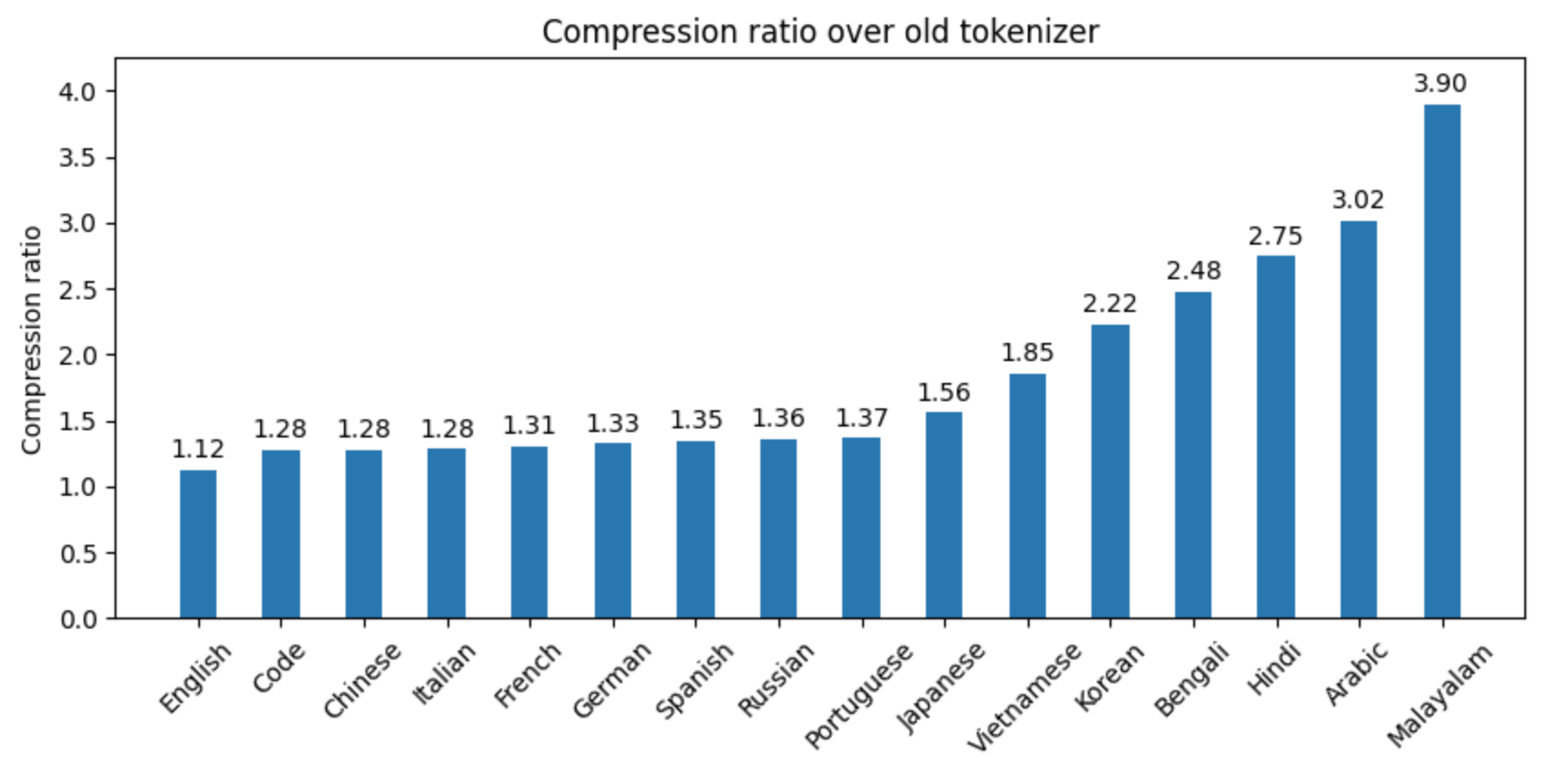
Tekken 在 100 多种语言上进行了训练,比之前 Mistral 模型使用的 SentencePiece 分词器更有效地压缩自然语言文本和源代码。特别是,它在压缩中文、意大利语、法语、德语、西班牙语和俄语的源代码时效率提高了约 30%。在压缩韩语和阿拉伯语方面,效率分别提高了 2 倍和 3 倍。与 Llama 3 分词器相比,Tekken 在压缩约 85% 的所有语言文本方面表现更出色。
我们的分词词汇表
我们的分词词汇表发布在 https://github.com/mistralai/mistral-common/tree/main/tests/data 文件夹中。让我们来看看我们的 v3 tekken 分词器的词汇表。
词汇表大小
我们的词汇表包含 13 万个词汇 token + 1 千个控制 token。
控制 token
我们的词汇表以 14 个控制 token 开头,这些是我们编码过程中用来表示特定指令或指示符的特殊 token。
<unk>
<s>
</s>
[INST]
[/INST]
[AVAILABLE_TOOLS]
[/AVAILABLE_TOOLS]
[TOOL_RESULTS]
[/TOOL_RESULTS]
[TOOL_CALLS]
<pad>
[PREFIX]
[MIDDLE]
[SUFFIX]
分词器不编码控制 token,这有助于防止所谓的提示注入情况。例如,控制 token “[INST]” 用于表示用户消息。
- 如果没有控制 token,分词器会将 “[INST]” 视为常规字符串并编码整个序列 “[INST] I love Paris [/INST]”。这可能会允许用户在其消息中包含 “[INST]” 和 “[/INST]” 标签,导致模型混淆,因为它可能将用户消息的一部分解释为助手消息。
- 有了控制 token,分词器会 instead 将控制 token 与编码后的消息连接起来:[INST] + encode(“I love Paris”) + [/INST]。这确保只有用户消息被编码,并且编码后的消息保证带有正确的 [INST] 和 [/INST] 标签。
你可能已经注意到我们有 1000 个控制 token 的槽位。剩余的 1000-14=986 个控制 token 槽位目前是空的,以便我们将来添加更多控制 token,同时也确保我们的词汇表大小为 131k (2^17)。计算机喜欢 2 的幂!
字节、字符和合并字符
下面是词汇表的两个例子。当字节序列不能解码成完整的 unicode 字符时(例如原始字节),token_str 为 null。
{
"rank": 0,
"token_bytes": "AA==",
"token_str": "\u0000"
},
...
{
"rank": 7613,
"token_bytes": "IO2D",
"token_str": null
},
在 Python 中运行我们的分词器
首先,让我们通过 pip install mistral-common tiktoken 安装我们的分词器和 tiktoken。
分词器安装完成后,在 Python 环境中,我们可以从 mistral_common 导入所需的模块。
from mistral_common.protocol.instruct.messages import (
UserMessage,
)
from mistral_common.protocol.instruct.request import ChatCompletionRequest
from mistral_common.protocol.instruct.tool_calls import (
Function,
Tool,
)
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
然后我们可以加载我们的分词器。
tokenizer = MistralTokenizer.v3(is_tekken=True)
model_name = "nemostral"
tokenizer = MistralTokenizer.from_model(model_name)
让我们对一系列包含不同类型消息的对话进行分词。
# Tokenize a list of messages
tokenized = tokenizer.encode_chat_completion(
ChatCompletionRequest(
tools=[
Tool(
function=Function(
name="get_current_weather",
description="Get the current weather",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
)
)
],
messages=[
UserMessage(content="What's the weather like today in Paris"),
],
model=model_name,
)
)
tokens, text = tokenized.tokens, tokenized.text
这里是“text”的输出,它是一个调试表示,供您检查。
<s>[AVAILABLE_TOOLS][{"type": "function", "function": {"name": "get_current_weather", "description": "Get the current weather", "parameters": {"type": "object", "properties": {"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"}, "format": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The temperature unit to use. Infer this from the users location."}}, "required": ["location", "format"]}}}][/AVAILABLE_TOOLS][INST]What's the weather like today in Paris[/INST]
要计算 token 数量,运行 len(tokens),我们得到 128 个 token。
v3 分词器
我们的 v3 分词器使用带有 SentencePiece 的字节对编码 (BPE),SentencePiece 是一个开源分词库,用于构建我们的分词词汇表。
在 BPE 中,分词过程首先将文本中的每个字节视为一个独立的 token。然后,它迭代地向词汇表中添加新的 token,这些新 token 是当前文本中出现频率最高的 token 对。例如,如果出现频率最高的 token 对是 "th" + "e",那么将创建一个新的 token "the",并将所有 "th"+"e" 的出现替换为新的 token "the"。这个过程一直持续到没有更多可替换的组合为止。
我们的分词词汇表
我们的分词词汇表发布在 https://github.com/mistralai/mistral-common/tree/main/tests/data 文件夹中。让我们来看看我们的 v3 分词器的词汇表。
词汇表大小
我们的词汇表包含 3.2 万个词汇 token + 768 个控制 token。这 3.2 万个词汇 token 包括 256 个字节以及 31,744 个字符和合并字符。
控制 token
我们的词汇表以 10 个控制 token 开头,这些是我们编码过程中用来表示特定指令或指示符的特殊 token。
<unk>
<s>
</s>
[INST]
[/INST]
[TOOL_CALLS]
[AVAILABLE_TOOLS]
[/AVAILABLE_TOOLS]
[TOOL_RESULTS]
[/TOOL_RESULTS]
字节
在控制 token 槽位之后,词汇表中有 256 个字节。一个字节是一个数字信息单元,由 8 位组成。每一位可以表示两个值中的一个,要么是 0,要么是 1。因此,一个字节可以表示 256 个不同的值。
<0x00>
<0x01>
...
任何字符,无论语言或符号如何,都可以由一个或多个字节序列表示。当一个词不在词汇表中时,它仍然可以通过对应于其单个字符的字节来表示。这对于处理未知词和字符非常重要。
字符和合并字符
最后,词汇表中还有字符和合并字符。这些 token 的顺序由它们在用于训练模型的数据中的频率决定,频率最高的排在词汇表的最前面。例如,“ ” (两个空格)、“ ” (四个空格)、“_t”、“in” 和 “er” 被发现是我们训练数据中最常见的 token。随着词汇表列表向下移动,token 的频率会降低。在词汇表文件的末尾,你可能会发现一些不太常见的字符,例如中文和韩文字符。这些字符频率较低,是因为它们在训练数据中遇到的次数较少,而不是因为它们在一般使用中不常见。
▁▁
▁▁▁▁
▁t
in
er
...
벨
ゼ
梦
在 Python 中运行我们的分词器
首先,让我们通过 pip install mistral-common 安装我们的分词器。
分词器安装完成后,在 Python 环境中,我们可以从 mistral_common 导入所需的模块。
from mistral_common.protocol.instruct.messages import (
AssistantMessage,
UserMessage,
ToolMessage
)
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.tool_calls import Function, Tool, ToolCall, FunctionCall
from mistral_common.protocol.instruct.request import ChatCompletionRequest
我们使用 MistralTokenizer 加载我们的分词器,并指定我们要加载的分词器版本。
tokenizer_v3 = MistralTokenizer.v3()
让我们对一系列包含不同类型消息的对话进行分词
tokenized = tokenizer_v3.encode_chat_completion(
ChatCompletionRequest(
tools=[
Tool(
function=Function(
name="get_current_weather",
description="Get the current weather",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
)
)
],
messages=[
UserMessage(content="What's the weather like today in Paris"),
AssistantMessage(
content=None,
tool_calls=[
ToolCall(
id="VvvODy9mT",
function=FunctionCall(
name="get_current_weather",
arguments='{"location": "Paris, France", "format": "celsius"}',
),
)
],
),
ToolMessage(
tool_call_id="VvvODy9mT", name="get_current_weather", content="22"
),
AssistantMessage(
content="The current temperature in Paris, France is 22 degrees Celsius.",
),
UserMessage(content="What's the weather like today in San Francisco"),
AssistantMessage(
content=None,
tool_calls=[
ToolCall(
id="fAnpW3TEV",
function=FunctionCall(
name="get_current_weather",
arguments='{"location": "San Francisco", "format": "celsius"}',
),
)
],
),
ToolMessage(
tool_call_id="fAnpW3TEV", name="get_current_weather", content="20"
),
],
model="test",
)
)
tokens, text = tokenized.tokens, tokenized.text
这里是“text”的输出,它是一个调试表示,供您检查。
'<s>[INST] What\'s the weather like today in Paris[/INST][TOOL_CALLS] [{"name": "get_current_weather", "arguments": {"location": "Paris, France", "format": "celsius"}, "id": "VvvODy9mT"}]</s>[TOOL_RESULTS] {"call_id": "VvvODy9mT", "content": 22}[/TOOL_RESULTS] The current temperature in Paris, France is 22 degrees Celsius.</s>[AVAILABLE_TOOLS] [{"type": "function", "function": {"name": "get_current_weather", "description": "Get the current weather", "parameters": {"type": "object", "properties": {"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"}, "format": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The temperature unit to use. Infer this from the users location."}}, "required": ["location", "format"]}}}][/AVAILABLE_TOOLS][INST] What\'s the weather like today in San Francisco[/INST][TOOL_CALLS] [{"name": "get_current_weather", "arguments": {"location": "San Francisco", "format": "celsius"}, "id": "fAnpW3TEV"}]</s>[TOOL_RESULTS] {"call_id": "fAnpW3TEV", "content": 20}[/TOOL_RESULTS]'
要计算 token 数量,运行 len(tokens),我们得到 302 个 token。
用例
NLP 任务
正如我们之前提到的,分词是自然语言处理 (NLP) 任务中的关键第一步。一旦我们对文本进行了分词,就可以使用这些 token 创建文本嵌入,它们是文本的密集向量表示。然后可以将这些嵌入用于各种 NLP 任务,例如文本分类、情感分析和机器翻译。
Mistral 的嵌入 API 将分词和嵌入步骤合并为一个,从而简化了此过程。使用此 API,我们可以轻松为给定文本创建文本嵌入,而无需单独对文本进行分词并从 token 创建嵌入。
如果您有兴趣了解更多关于如何使用 Mistral 嵌入 API 的信息,请务必查阅我们的嵌入指南,其中提供了详细的说明和示例。
Token 计数
Mistral AI 的 LLM API 端点根据输入文本中的 token 数量收费。
为了帮助您估算成本,我们的分词 API 可以轻松计算文本中的 token 数量。只需运行 len(tokens),如上例所示,即可获取文本中的 token 总数,然后您可以根据我们的定价信息估算成本。