采样:我们的采样设置概述
在此,我们将讨论影响大型语言模型(LLM)输出的采样设置。本指南涵盖了诸如 **温度 (Temperature)**、**N 值 (N)**、**Top P**、**存在惩罚 (Presence Penalty)** 和 **频率惩罚 (Frequency Penalty)** 等参数,并解释了如何调整它们。无论您是想生成创意内容还是确保准确响应,理解这些设置都至关重要。
让我们来探讨每个参数,并学习如何有效地微调 LLM 输出。
N 个补全
N 个补全
N 表示每次请求返回的补全数量。当您想为单个输入生成多个响应时,此参数非常有用。每个补全都是模型生成的独特响应,提供多种输出供您选择。
关键点
- 多重响应:通过将
N设置为大于 1 的值,您可以为相同的输入获得多个响应。 - 成本效益:无论请求的补全数量如何,输入 token 只会计费一次。这使得探索不同的可能性具有成本效益。
示例
以下是如何在 API 中使用 N 参数的示例:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
model = "ministral-3b-latest"
client = Mistral(api_key=api_key)
chat_response = client.chat.complete(
model=model,
messages=[
{
"role": "user",
"content": "What is the best mythical creature? Answer with a single word.",
},
],
temperature = 1, # Increasing randomness and diversity of the output, this is required to be higher than 0 to have diverse outputs
n = 10 # Number of completions
)
for i, choice in enumerate(chat_response.choices):
print(choice.message.content)
输出
Phoenix.
Dragon
Dragon
Unicorn
Unicorn
Phoenix
Unicorn
Dragon
Dragon.
Unicorn
在此示例中,模型为相同的输入提示词生成了 10 个响应。这让您可以查看各种可能的答案,并选择最符合您需求的那个。
温度
温度
大型语言模型(LLM)中的**温度 (Temperature)** 控制输出多样性。较低的值使模型更具确定性,侧重于可能的响应以确保准确性。较高的值会增加创造性和多样性。在文本生成过程中,LLM 使用 softmax 函数预测带有相关概率的 token。温度会调整这些概率:较高的温度会使分布变平,使输出更多样化,而较低的温度会放大差异,偏向更可能出现的 token。
可视化
为了更好地理解其基本原理及其对概率分布的影响,以下是一个简单提示词下温度的可视化效果:“哪种神话生物最好?用一个词回答。”
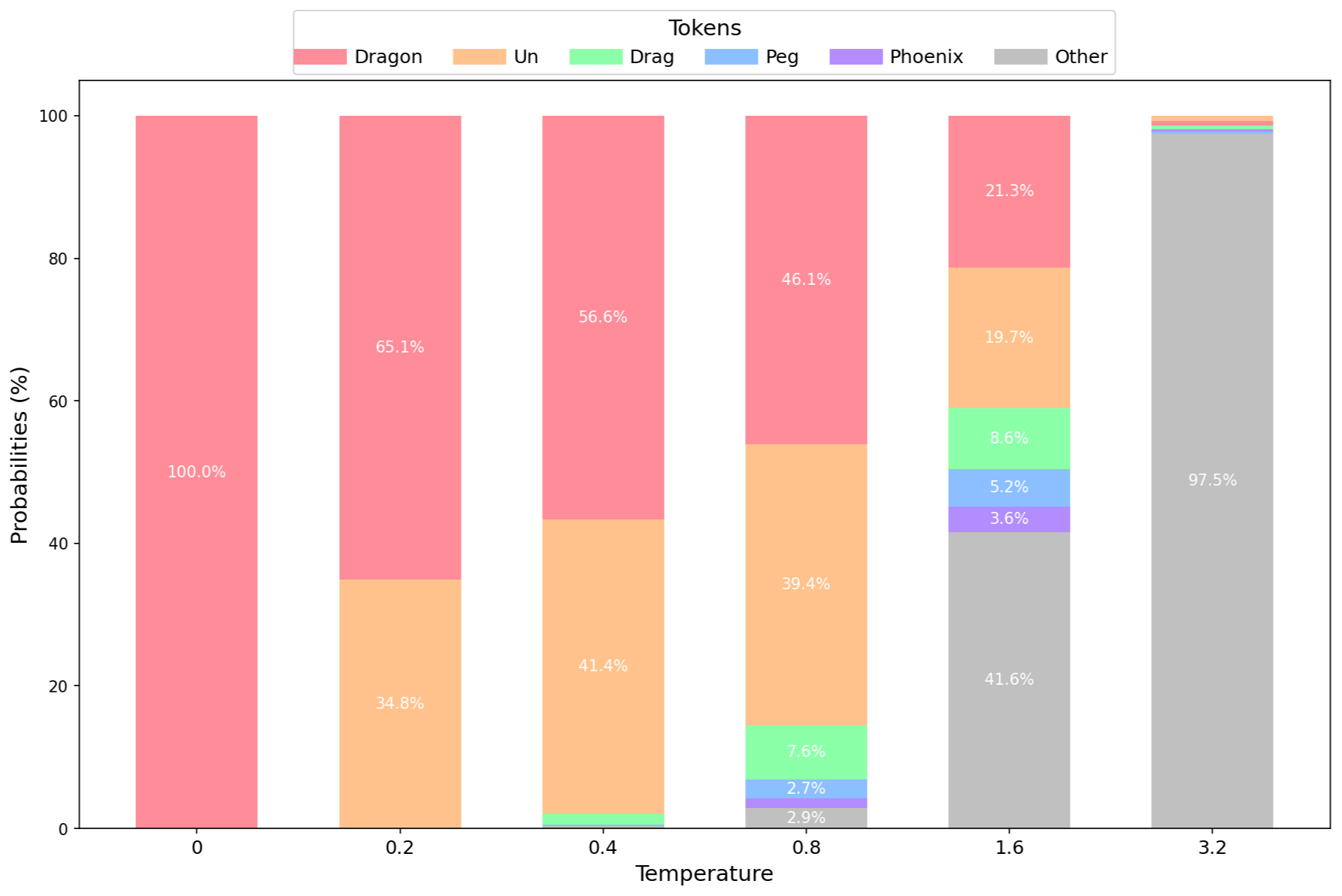 柱状图示例,比较了使用 Mistral 7B 4 位精度模型在不同
柱状图示例,比较了使用 Mistral 7B 4 位精度模型在不同 Temperature 值下的分布以及前 5 个 token。**温度 (Temperature)** 显著影响 LLM 中的概率分布。在温度为 0 时,模型总是输出最可能的 token,例如:“**龙 (Dragon)**”。将温度提高到 0.2 会引入变异性,允许出现诸如“**独**”(如“**独**角兽”)之类的 token。进一步提高温度会揭示更多样化的 token:第三个 token 可能仍然是“**龙**”(指“**龙 (Dragon)**”),但第四个可能以“**飞马**”(指“**飞马 (Pegasus)**”)开头,第五个则是“**凤凰 (Phoenix)**”。更高的温度使不太可能出现的 token 变得更可能,从而增强了模型输出的多样性。
API
您可以通过我们的客户端轻松设置温度值,让我们用我们的 API 进行实验。
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
model = "ministral-3b-latest"
client = Mistral(api_key=api_key)
chat_response = client.chat.complete(
model = model,
messages = [
{
"role": "user",
"content": "What is the best mythical creature? Answer with a single word.",
},
],
temperature = 0.1,
n = 10
)
for i, choice in enumerate(chat_response.choices):
print(choice.message.content)
Dragon
Dragon
Dragon
Dragon
Dragon
Dragon
Dragon
Dragon
Dragon
Dragon
模型大部分回答是龙!让我们尝试更高的温度来获得更多样化的输出,将其设置为 temperature = 1。
Unicorn
Dragon
Phoenix
Unicorn
Dragon
Phoenix.
Dragon.
Phoenix
Dragon
Unicorn.
输出结果更加多样化,模型更频繁地回答不同的生物,我们得到了“龙”、“独角兽”和“凤凰”。
最佳温度
没有一种温度适用于所有用例,但一些指导方针可以帮助您为您的应用找到最佳温度。
确定性
- 要求:需要一致、准确响应的任务,例如数学、分类、医疗保健或推理。
- 温度:使用非常低的值,有时不为 null 以增加轻微的独特性。
例如,一个分类智能体应该使用温度 0 来总是选择最佳 token。一个数学聊天助手可以使用非常低的温度值来避免重复,同时保持准确性。
创造性
- 要求:需要多样、独特文本的任务,例如头脑风暴、写小说、创作标语或角色扮演。
- 温度:使用较高的值,但避免过高的温度以防止产生随机和无意义的输出。
考虑权衡:较高的温度会增加创造性,但可能会降低质量和准确性。
Top P
Top P
Top P 是一种设置,它根据概率阈值限制语言模型考虑的 token。它有助于专注于最可能出现的 token,从而提高输出质量。
可视化
对于这些示例,我们首先设置温度,然后应用 50% 的 Top P。请注意,温度为 0 时是确定性的,在这种情况下 Top P 不相关。
过程如下:
- 应用温度。
- 使用 Top P (0.5) 只保留最可能出现的 token。
- 调整剩余 token 的概率。
我们将可视化不同温度值下针对以下问题的 token 概率分布:
- “哪种神话生物最好?用一个词回答。”
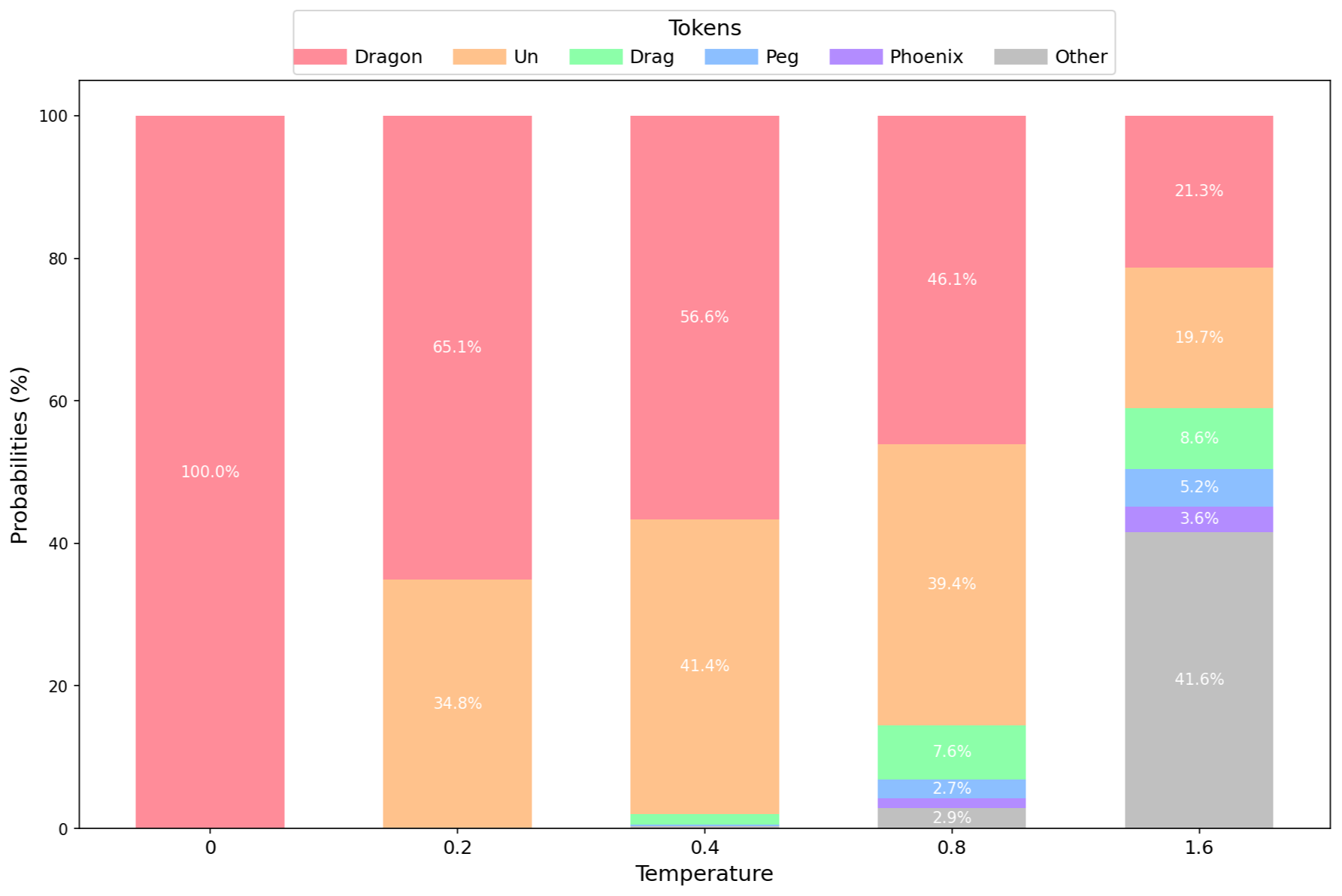
使用 Mistral 7B 4 位精度模型在不同温度值下的分布以及前 5 个 token。
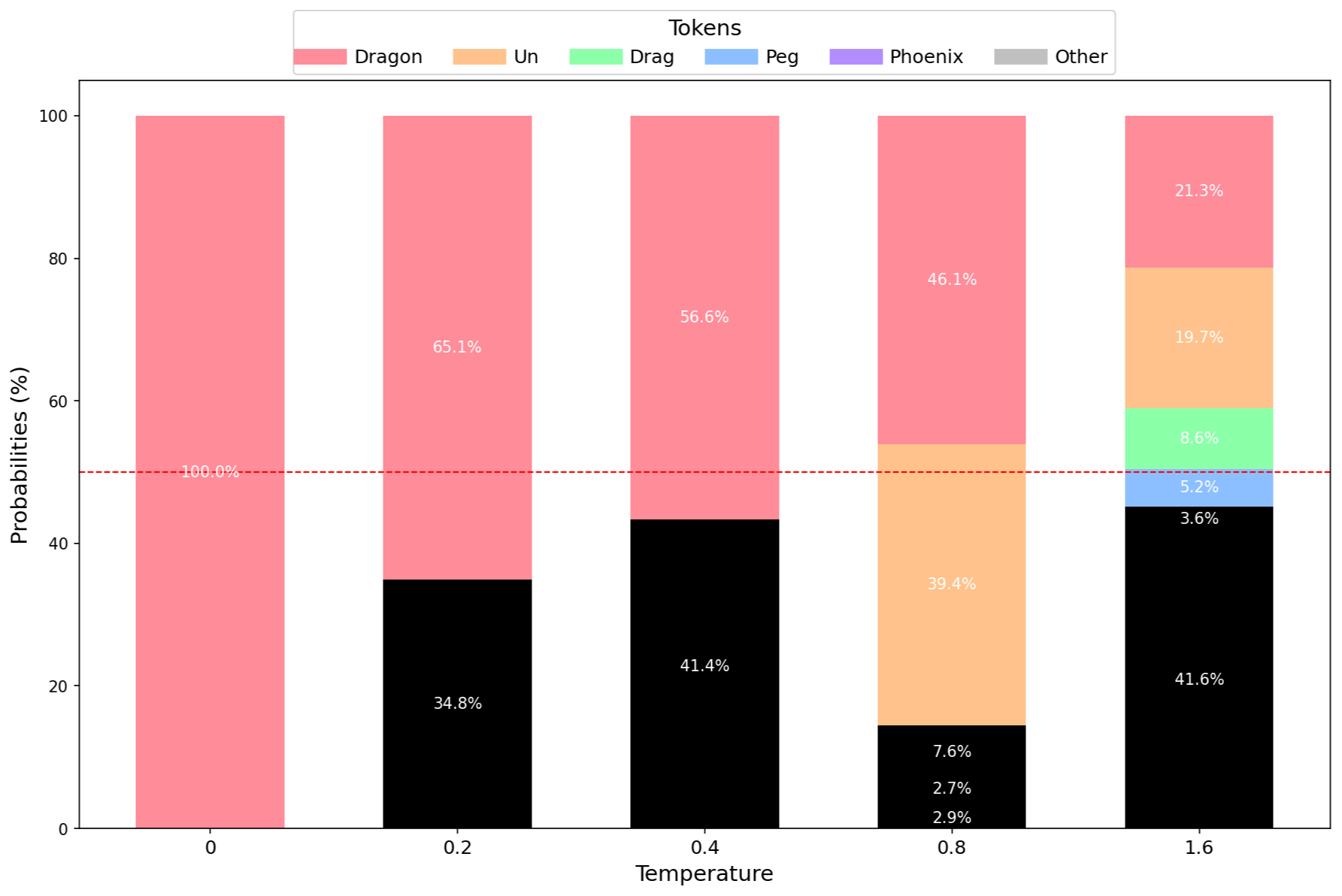
Top P 只考虑概率累积达到 50% 的前几个 token。
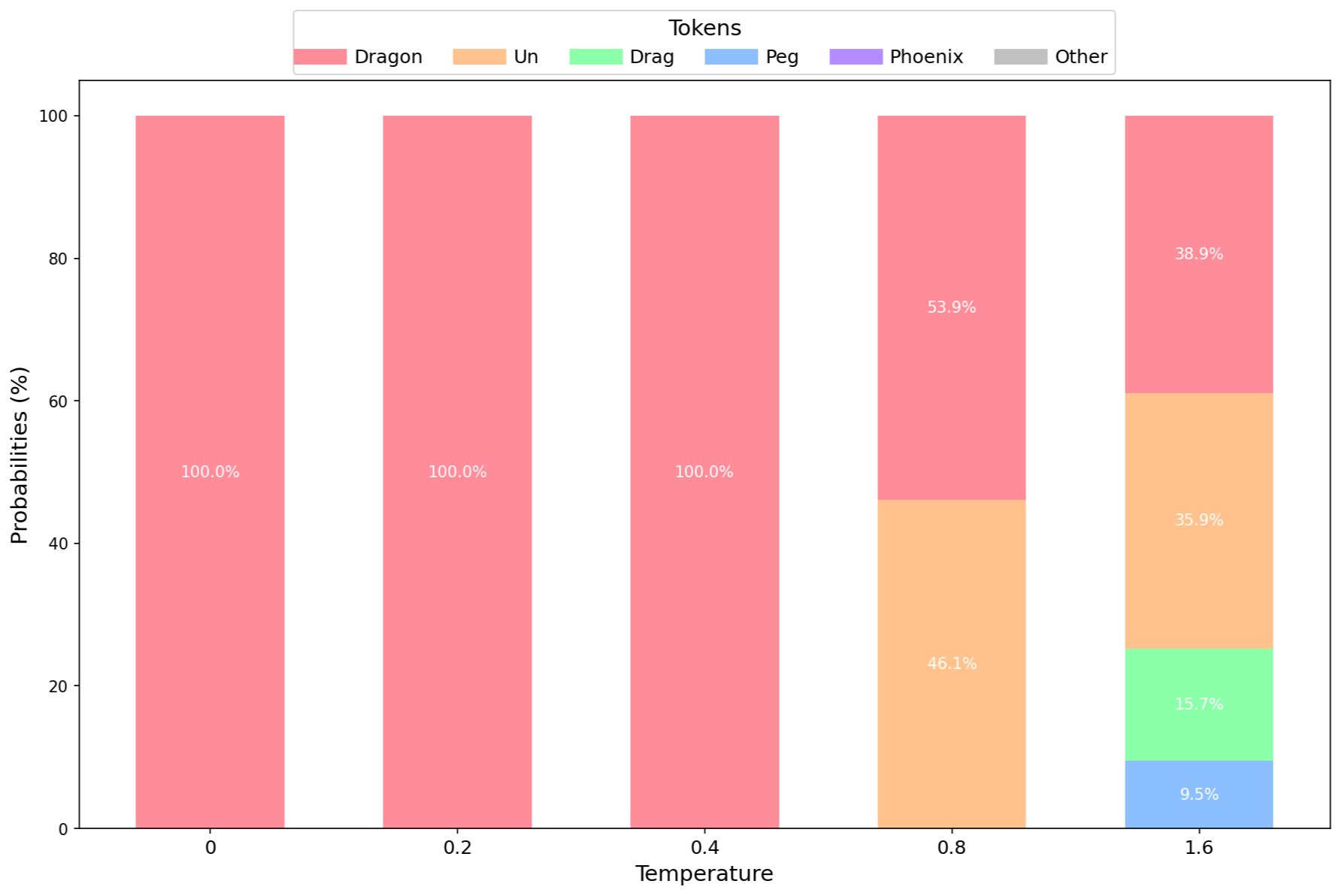
其他 token 的概率设置为 0,并调整剩余 token 的概率。
Top P 确保只考虑高质量的 token,通过排除不太可能出现的 token 来维持输出质量。平衡温度和 Top P 具有挑战性,因此建议固定一个参数并调整另一个。然而,您应该进行实验以找到最适合您用例的设置!
总结
- Top P 的作用:Top P 根据概率阈值限制考虑的 token,专注于最可能出现的 token 以提高输出质量。
- 与温度的相互作用:Top P 在温度之后应用。
- 对输出的影响:Top P 避免考虑非常不可能出现的 token,保持输出质量和连贯性。
- 平衡温度和 Top P:平衡两者具有挑战性。从固定一个参数开始并调整另一个,进行实验以找到最佳设置。
示例
以下是如何使用我们的 Python 客户端使用 Top P 参数的示例:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
model = "ministral-3b-latest"
client = Mistral(api_key=api_key)
chat_response = client.chat.complete(
model=model,
messages=[
{
"role": "user",
"content": "What is the best mythical creature? Answer with a single word.",
},
],
temperature=1,
top_p=0.5,
n=10
)
for i, choice in enumerate(chat_response.choices):
print(choice.message.content)
输出
Unicorn
Unicorn
Unicorn
Unicorn
Dragon
Unicorn
Dragon
Dragon
Dragon
Dragon
输出表格
| 温度 0.1 | 温度 1 | 温度 1 和 Top P 50% |
|---|---|---|
| 龙 | 独角兽 | 独角兽 |
| 龙 | 龙 | 独角兽 |
| 龙 | 凤凰 | 独角兽 |
| 龙 | 独角兽 | 独角兽 |
| 龙 | 龙 | 龙 |
| 龙 | 凤凰。 | 独角兽 |
| 龙 | 龙。 | 龙 |
| 龙 | 凤凰 | 龙 |
| 龙 | 龙 | 龙 |
| 龙 | 独角兽。 | 龙 |
在此示例中,模型仅考虑累积达到 50% 概率阈值的前几个 token 来生成响应。这确保了输出保持一定的均匀多样性,同时仍然只取最佳 token,在此例中只有 2 个 token 达到了 50% 的阈值。
惩罚
存在/频率惩罚
存在惩罚
存在惩罚 (Presence Penalty) 决定了模型对词语或短语重复的惩罚程度。它鼓励模型使用更广泛的词语和短语,使输出更具多样性和创造性。
- 范围: [-2, 2]
- 默认值: 0
更高的存在惩罚鼓励模型避免重复已在输出中出现的词语或短语,确保文本更具变化和创造性。
存在惩罚特别之处在于,它是一种应用于所有至少使用过一次的 token 的**一次性调整**。它降低了重复任何已出现的 token 的可能性。这鼓励模型使用多样化的 token,从而促进输出的创造性和多样性。
频率惩罚
频率惩罚 (Frequency Penalty) 是一个参数,它根据词语在生成文本中的频率来惩罚重复。它有助于促进输出的多样性并减少重复。
- 范围: [-2, 2]
- 默认值: 0
更高的频率惩罚会阻止模型重复在输出中频繁出现的词语。这确保了生成的文本更具变化且重复性更低。
频率惩罚特别之处在于,它是一个随 token 在生成文本中出现频率而增加的值,是一种**累积惩罚**,token 被采样的次数越多,惩罚越高。它降低了重复任何已频繁出现的 token 的可能性。这确保了生成的文本更具变化且重复性更低。
存在惩罚与频率惩罚的区别
- 存在惩罚 (Presence Penalty):这是一种一次性的累加贡献,适用于所有至少已被采样一次的 token。它鼓励模型在生成的文本中包含多样化的 token。
- 频率惩罚 (Frequency Penalty):这是一种与特定 token 已被采样的次数成比例的贡献。它阻止模型在生成的文本中过于频繁地重复相同的词语或短语。
这两个参数都可以进行调整,以塑造生成文本的质量和多样性。这些参数的最佳值会因具体任务和期望结果而异。
- 无惩罚
- 存在惩罚
- 频率惩罚
无存在惩罚示例
以下是没有使用 Presence Penalty 参数时的输出示例:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
model = "ministral-3b-latest"
client = Mistral(api_key=api_key)
chat_response = client.chat.complete(
model=model,
messages=[
{"role": "user",
"content": "List 10 possible titles for a fantasy book. Give a list only."}
],
temperature=0
)
print(chat_response.choices[0].message.content)
无存在惩罚时的输出
1. "The Shattered Crown"
2. "Whispers of the Old Magic"
3. "Echoes of the Forgotten Realm"
4. "The Chronicles of the Silver Moon"
5. "The Enchanted Forest's Secret"
6. "The Last Dragon's Legacy"
7. "The Shadowed Path"
8. "The Song of the Siren's Call"
9. "The Lost City of the Stars"
10. "The Whispering Winds of Destiny"
有存在惩罚示例
以下是如何在 API 中使用 Presence Penalty 参数的示例:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
model = "ministral-3b-latest"
client = Mistral(api_key=api_key)
chat_response = client.chat.complete(
model=model,
messages=[
{"role": "user",
"content": "List 10 possible titles for a fantasy book. Give a list only."}
],
temperature=0,
presence_penalty=2
)
print(chat_response.choices[0].message.content)
有存在惩罚时的输出
1. "The Shattered Crown"
2. "Whispers of the Old Magic"
3. "Echoes of Eternity"
4. "Shadows of the Forgotten Realm"
5. "Chronicles of the Enchanted Forest"
6. "The Last Dragon's Roar"
7. "Mysteries of the Hidden City"
8. "Legends of the Lost Kingdom"
9. "The Whispering Winds"
10. "The Unseen War"
输出列表与第一个列表已经略有不同,受到了已出现 token 的存在惩罚的影响。例如,与没有存在惩罚相比,作为 token 的
The数量更少。
有频率惩罚示例
以下是如何在 API 中使用 Frequency Penalty 参数的示例:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
model = "ministral-3b-latest"
client = Mistral(api_key=api_key)
chat_response = client.chat.complete(
model=model,
messages=[
{"role": "user",
"content": "List 10 possible titles for a fantasy book. Give a list only."}
],
temperature=0,
frequency_penalty=2
)
print(chat_response.choices[0].message.content)
有频率惩罚时的输出
1. "The Shattered Crown"
2. "Whispers of the Old Magic"
3. "Echoes of Eternity"
4. "The Forgotten Realm"
5. "Shadows of the Lost City"
6. "Chronicles of the Enchanted Forest"
7. The Last Dragon's Roar
8."The Veil Between Worlds"
9."The Song of the Siren's Call"
10."Legends in Stone"
输出比之前更具多样性,但请注意,在列表的第 7 个值之后,诸如
_"和单引号之类的 token 也开始受到严重影响,这表明频率惩罚作为一种累积惩罚在长期内影响更强。
惩罚是一个敏感参数,对长上下文和长输出查询可能产生显著影响。它们还可以帮助避免模型可能陷入的高度重复循环,使其成为一个有价值的参数。