嵌入
嵌入是文本的向量表示,通过它们在高维向量空间中的位置捕捉段落的语义含义。Mistral AI 嵌入 API 提供了文本领域的尖端、最先进的嵌入,可用于许多自然语言处理 (NLP) 任务。在本指南中,我们将介绍嵌入 API 的基础知识,包括如何衡量文本嵌入之间的距离,并探讨其主要用例:聚类和分类。
Mistral Embed API
要使用 Mistral AI 的嵌入 API 生成文本嵌入,我们可以向 API 端点发出请求,并指定嵌入模型 mistral-embed,同时提供一个输入文本列表。API 将返回相应的嵌入作为数值向量,可用于 NLP 应用程序中的进一步分析或处理。
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
model = "mistral-embed"
client = Mistral(api_key=api_key)
embeddings_batch_response = client.embeddings.create(
model=model,
inputs=["Embed this sentence.", "As well as this one."],
)
输出 embeddings_batch_response 是一个包含嵌入和 token 使用信息的 EmbeddingResponse 对象。
EmbeddingResponse(
id='eb4c2c739780415bb3af4e47580318cc', object='list', data=[
Data(object='embedding', embedding=[-0.0165863037109375,...], index=0),
Data(object='embedding', embedding=[-0.0234222412109375,...], index=1)],
model='mistral-embed', usage=EmbeddingResponseUsage(prompt_tokens=15, total_tokens=15)
)
让我们看看第一个嵌入的长度
len(embeddings_batch_response.data[0].embedding)
它返回 1024,这意味着我们的嵌入维度是 1024。mistral-embed 模型为每个文本字符串生成维度为 1024 的嵌入向量,无论文本长度如何。值得注意的是,虽然更高维度的嵌入可以更好地捕捉文本信息并提高 NLP 任务的性能,但它们可能需要更多的计算资源用于托管和推理,并且可能导致存储和处理这些嵌入时延迟和内存使用量增加。在设计依赖文本嵌入的 NLP 系统时,应考虑性能和计算资源之间的这种权衡。
距离度量
在文本嵌入领域,含义或上下文相似的文本倾向于在该空间中彼此靠近,这通过它们向量之间的距离来衡量。这是因为模型在训练过程中学会了将语义相关的文本分组在一起。
让我们看一个简单的例子。为了简化处理文本嵌入,我们可以将嵌入 API 封装在这个函数中
from sklearn.metrics.pairwise import euclidean_distances
def get_text_embedding(inputs):
embeddings_batch_response = client.embeddings.create(
model=model,
inputs=inputs
)
return embeddings_batch_response.data[0].embedding
假设我们有两个句子:一个关于猫,另一个关于书。我们想找出每个句子与参考句子“书是镜子:你只能在其中看到你内心已经拥有的东西”的相似度。我们可以看到,参考句子嵌入与书句子嵌入之间的距离小于参考句子嵌入与猫句子嵌入之间的距离。
sentences = [
"A home without a cat — and a well-fed, well-petted and properly revered cat — may be a perfect home, perhaps, but how can it prove title?",
"I think books are like people, in the sense that they'll turn up in your life when you most need them"
]
embeddings = [get_text_embedding([t]) for t in sentences]
reference_sentence = "Books are mirrors: You only see in them what you already have inside you"
reference_embedding = get_text_embedding([reference_sentence])
for t, e in zip(sentences, embeddings):
distance = euclidean_distances([e], [reference_embedding])
print(t, distance)
输出
A home without a cat — and a well-fed, well-petted and properly revered cat — may be a perfect home, perhaps, but how can it prove title? [[0.80094257]]
I think books are like people, in the sense that they'll turn up in your life when you most need them [[0.58162089]]
在上面的例子中,我们使用欧几里得距离来衡量嵌入向量之间的距离(请注意,由于 Mistral AI 嵌入是范数 1,因此余弦相似度、点积或欧几里得距离都是等效的)。
释义检测
另一个潜在用例是释义检测。在这个简单的例子中,我们有一个包含三个句子的列表,我们想找出其中是否有任意两个句子是彼此的释义。如果两个句子嵌入之间的距离很小,则表明这两个句子在语义上相似,可能是潜在的释义。
结果表明前两个句子在语义上相似,可能是潜在的释义,而第三个句子则差异较大。这只是一个非常简单的例子。但这种方法可以扩展到现实世界应用中更复杂的情况,例如检测社交媒体帖子、新闻文章或客户评论中的释义。
import itertools
sentences = [
"Have a safe happy Memorial Day weekend everyone",
"To all our friends at Whatsit Productions Films enjoy a safe happy Memorial Day weekend",
"Where can I find the best cheese?",
]
sentence_embeddings = [get_text_embedding([t]) for t in sentences]
sentence_embeddings_pairs = list(itertools.combinations(sentence_embeddings, 2))
sentence_pairs = list(itertools.combinations(sentences, 2))
for s, e in zip(sentence_pairs, sentence_embeddings_pairs):
print(s, euclidean_distances([e[0]], [e[1]]))
输出
('Have a safe happy Memorial Day weekend everyone', 'To all our friends at Whatsit Productions Films enjoy a safe happy Memorial Day weekend') [[0.54326686]]
('Have a safe happy Memorial Day weekend everyone', 'Where can I find the best cheese?') [[0.92573978]]
('To all our friends at Whatsit Productions Films enjoy a safe happy Memorial Day weekend', 'Where can I find the best cheese?') [[0.9114184]]
批量处理
Mistral AI 嵌入 API 设计用于批量处理文本,以提高效率和速度。在此示例中,我们将通过加载 Kaggle 上的 Symptom2Disease 数据集来演示这一点,该数据集包含 1200 行,其中有两列:“label”和“text”。“label”列表示疾病类别,而“text”列描述与该疾病相关的症状。
我们编写了一个函数 get_embeddings_by_chunks,它将数据分割成块,然后将每个块发送到 Mistral AI 嵌入 API 以获取嵌入。然后我们将嵌入保存为数据框中的新列。请注意,API 将在未来提供自动分块功能,因此用户无需在发送数据之前手动将数据分割成块。
import pandas as pd
df = pd.read_csv(
"https://raw.githubusercontent.com/mistralai/cookbook/main/data/Symptom2Disease.csv",
index_col=0,
)
def get_embeddings_by_chunks(data, chunk_size):
chunks = [data[x : x + chunk_size] for x in range(0, len(data), chunk_size)]
embeddings_response = [
client.embeddings.create(model=model, inputs=c) for c in chunks
]
return [d.embedding for e in embeddings_response for d in e.data]
df["embeddings"] = get_embeddings_by_chunks(df["text"].tolist(), 50)
df.head()
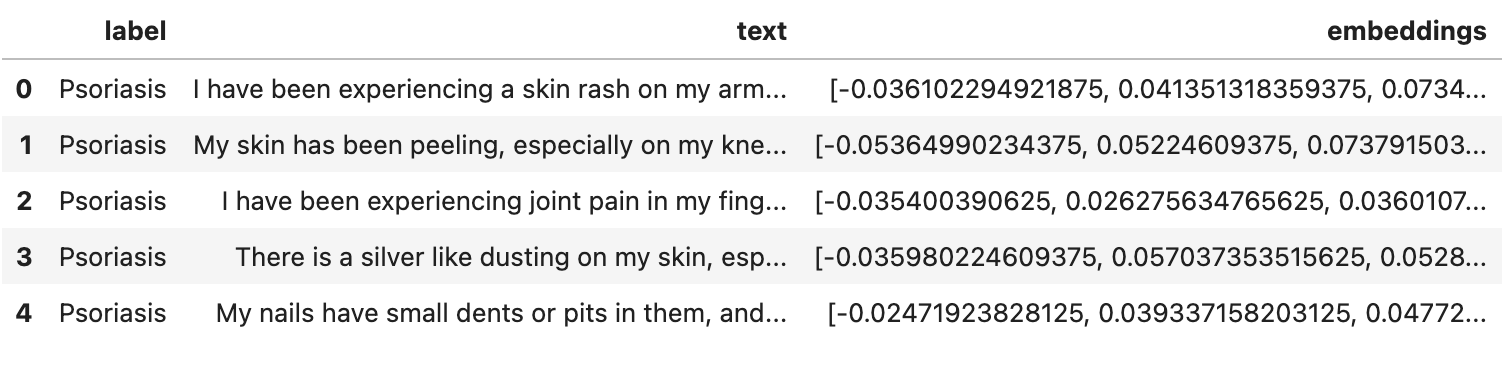
t-SNE 嵌入可视化
我们之前提到过,我们的嵌入有 1024 维,这使得它们无法直接可视化。因此,为了可视化我们的嵌入,我们可以使用 t-SNE 等降维技术将我们的嵌入投影到更容易可视化的低维空间中。
在此示例中,我们将嵌入转换为 2 维,并创建一个 2D 散点图,显示不同疾病嵌入之间的关系。
import seaborn as sns
from sklearn.manifold import TSNE
import numpy as np
tsne = TSNE(n_components=2, random_state=0).fit_transform(np.array(df['embeddings'].to_list()))
ax = sns.scatterplot(x=tsne[:, 0], y=tsne[:, 1], hue=np.array(df['label'].to_list()))
sns.move_legend(ax, 'upper left', bbox_to_anchor=(1, 1))
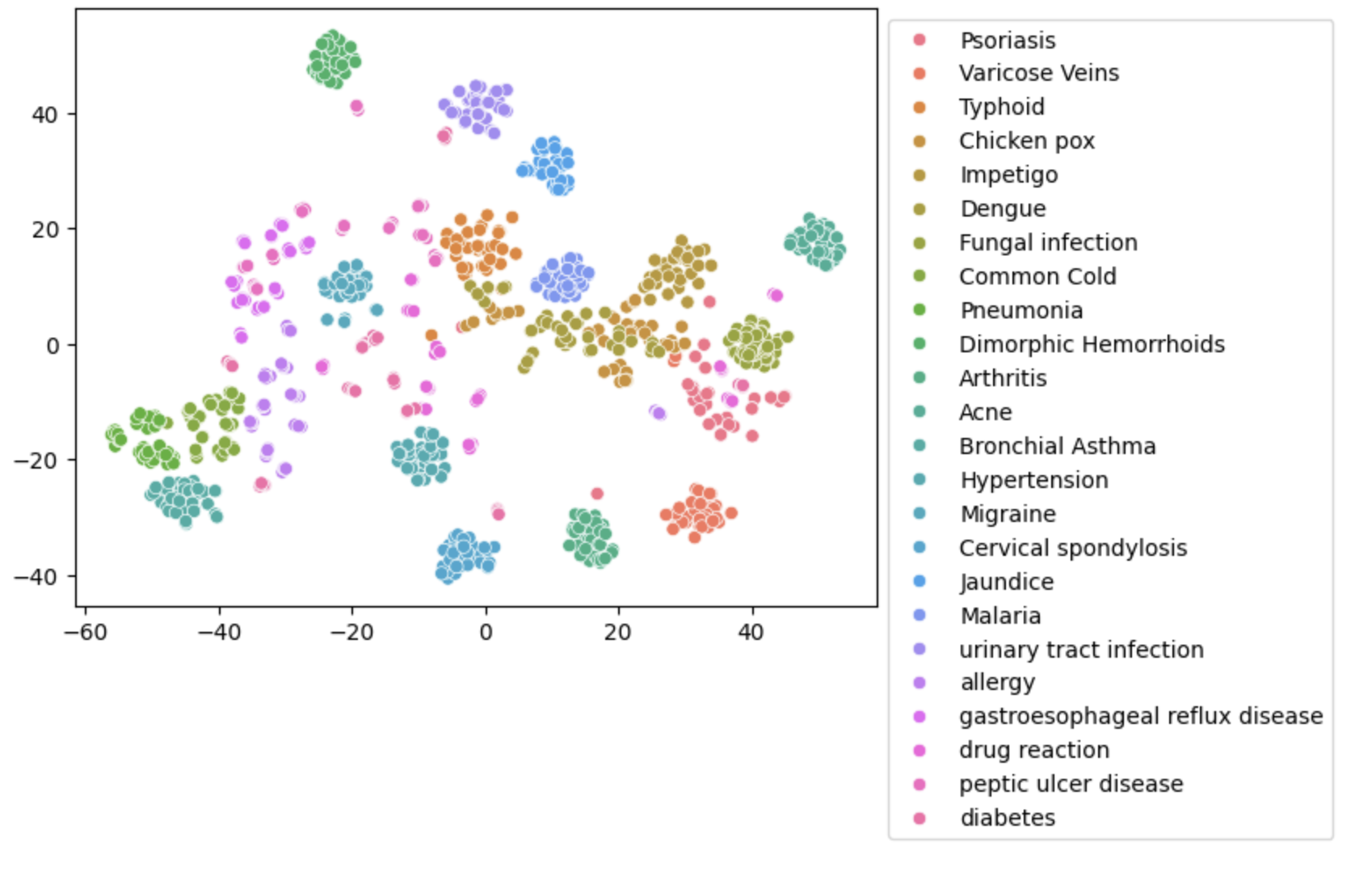
与 fastText 的比较
我们可以将其与 fastText 进行比较,fastText 是一种流行的开源嵌入模型。然而,在检查 t-SNE 嵌入图时,我们注意到 fastText 嵌入未能清楚地分离具有匹配标签的数据点。
import fasttext.util
fasttext.util.download_model('en', if_exists='ignore') # English
ft = fasttext.load_model('cc.en.300.bin')
df['fasttext_embeddings'] = df['text'].apply(lambda x: ft.get_word_vector(x).tolist())
tsne = TSNE(n_components=2, random_state=0).fit_transform(np.array(df['fasttext_embeddings'].to_list()))
ax = sns.scatterplot(x=tsne[:, 0], y=tsne[:, 1], hue=np.array(df['label'].to_list()))
sns.move_legend(ax, 'upper left', bbox_to_anchor=(1, 1))
分类
文本嵌入可用作机器学习模型的输入特征,例如分类和聚类。在此示例中,我们使用分类模型根据疾病描述文本的嵌入来预测疾病标签。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# Create a train / test split
train_x, test_x, train_y, test_y = train_test_split(
df["embeddings"], df["label"], test_size=0.2
)
# Normalize features
scaler = StandardScaler()
train_x = scaler.fit_transform(train_x.to_list())
test_x = scaler.transform(test_x.to_list())
# Train a classifier and compute the test accuracy
# For a real problem, C should be properly cross validated and the confusion matrix analyzed
clf = LogisticRegression(random_state=0, C=1.0, max_iter=500).fit(
train_x, train_y.to_list()
)
# you can also try the sag algorithm:
# clf = LogisticRegression(random_state=0, C=1.0, max_iter=1000, solver='sag').fit(train_x, train_y)
print(f"Precision: {100*np.mean(clf.predict(test_x) == test_y.to_list()):.2f}%")
输出
Precision: 98.75%
在使用我们的嵌入数据训练分类器后,我们可以尝试分类其他文本
# Classify a single example
text = "I've been experiencing frequent headaches and vision problems."
clf.predict([get_text_embedding([text])])
输出
'Migraine'
与 fastText 的比较
此外,让我们看看在此分类任务中使用 fastText 嵌入的性能。与使用 fastText 嵌入相比,分类模型使用 Mistral AI 嵌入模型似乎取得了更好的性能。
# Create a train / test split
train_x, test_x, train_y, test_y = train_test_split(
df["fasttext_embeddings"], df["label"], test_size=0.2
)
# Normalize features
scaler = StandardScaler()
train_x = scaler.fit_transform(train_x.to_list())
test_x = scaler.transform(test_x.to_list())
# Train a classifier and compute the test accuracy
# For a real problem, C should be properly cross validated and the confusion matrix analyzed
clf = LogisticRegression(random_state=0, C=1.0, max_iter=500).fit(
train_x, train_y.to_list()
)
# you can also try the sag algorithm:
# clf = LogisticRegression(random_state=0, C=1.0, max_iter=1000, solver='sag').fit(train_x, train_y)
print(f"Precision: {100*np.mean(clf.predict(test_x) == test_y.to_list()):.2f}%")
输出
Precision: 86.25%
聚类
如果我们没有疾病标签怎么办?从数据中获得见解的一种方法是通过聚类。聚类是一种无监督的机器学习技术,它根据数据点在某些特征方面的相似性将相似的数据点分组在一起。在文本嵌入的上下文中,我们可以使用每个嵌入之间的距离作为相似性的度量,并将嵌入在高维空间中彼此靠近的数据点分组在一起。
既然我们已经知道有 24 个簇,那么就使用包含 24 个簇的 K-means 聚类。然后我们可以检查几个例子,验证单个簇中的例子是否彼此相似。例如,看看簇 23 的前三行。我们可以看到它们在症状方面看起来非常相似。
from sklearn.cluster import KMeans
model = KMeans(n_clusters=24, max_iter=1000)
model.fit(df['embeddings'].to_list())
df["cluster"] = model.labels_
print(*df[df.cluster==23].text.head(3), sep='\n\n')
输出
I have been feeling extremely tired and weak, and I've also been coughing a lot with difficulty breathing. My fever is very high, and I'm producing a lot of mucus when I cough.
I've got a cough that won't go away, and I'm exhausted. I've been coughing up thick mucous and my fever is also pretty high.
I have a persistent cough and have been feeling quite fatigued. My fever is through the roof, and I'm having trouble breathing. When I cough, I also cough up a lot of mucous.
检索
我们的嵌入模型在检索任务中表现出色,因为它是在考虑到检索的情况下进行训练的。嵌入在实现检索增强生成 (RAG) 系统方面也非常有用,该系统使用从知识库中检索到的相关信息来生成响应。从高层次上看,我们将知识库(无论是本地目录、文本文件还是内部维基)嵌入为文本嵌入并存储在向量数据库中。然后,根据用户的查询,我们检索最相似的嵌入,这些嵌入代表了知识库中的相关信息。最后,我们将这些相关的嵌入馈送到大型语言模型中,以生成针对用户查询和上下文定制的响应。如果您对 RAG 系统如何工作以及如何实现基本 RAG 感兴趣,请查看我们之前关于此主题的指南。